Note
Go to the end to download the full example code
First Demo#
This Demo will showcase the feature estimation and exemplar analysis using simulated data.
import numpy as np
from matplotlib import pyplot as plt
import py_neuromodulation as nm
from py_neuromodulation import nm_analysis, nm_define_nmchannels, nm_plots
Data Simulation#
We will now generate some exemplar data with 10 second duration for 6 channels with a sample rate of 1 kHz.
def generate_random_walk(NUM_CHANNELS, TIME_DATA_SAMPLES):
# from https://towardsdatascience.com/random-walks-with-python-8420981bc4bc
dims = NUM_CHANNELS
step_n = TIME_DATA_SAMPLES - 1
step_set = [-1, 0, 1]
origin = (np.random.random([1, dims]) - 0.5) * 1 # Simulate steps in 1D
step_shape = (step_n, dims)
steps = np.random.choice(a=step_set, size=step_shape)
path = np.concatenate([origin, steps]).cumsum(0)
return path.T
NUM_CHANNELS = 6
sfreq = 1000
TIME_DATA_SAMPLES = 10 * sfreq
data = generate_random_walk(NUM_CHANNELS, TIME_DATA_SAMPLES)
time = np.arange(0, TIME_DATA_SAMPLES / sfreq, 1 / sfreq)
plt.figure(figsize=(8, 4), dpi=100)
for ch_idx in range(data.shape[0]):
plt.plot(time, data[ch_idx, :])
plt.xlabel("Time [s]")
plt.ylabel("Amplitude")
plt.title("Example random walk data")
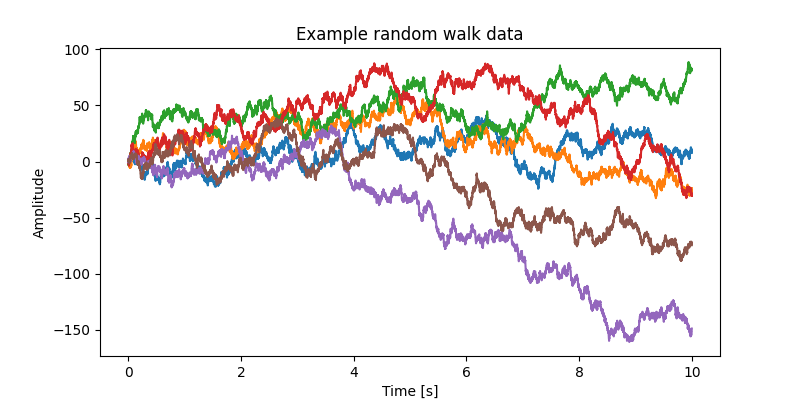
Text(0.5, 1.0, 'Example random walk data')
Now let’s define the necessary setup files we will be using for data preprocessing and feature estimation. Py_neuromodualtion is based on two parametrization files: the nm_channels.tsv and the nm_setting.json.
nm_channels#
The nm_channel dataframe. This dataframe contains the columns
Column name |
Description |
|---|---|
name |
name of the channel |
rereference |
different channel name for bipolar re-referencing, or average for common average re-referencing |
used |
0 or 1, channel selection |
target |
0 or 1, for some decoding applications we can define target channels, e.g. EMG channels |
type |
channel type according to the mne-python toolbox e.g. ecog, eeg, ecg, emg, dbs, seeg etc. |
status |
good or bad, used for channel quality indication |
new_name |
this keyword can be specified to indicate for example the used rereferncing scheme |
The nm_stream_abc can either be created as a .tsv text file, or as a pandas
DataFrame. There are some helper functions that let you create the
nm_channels without much effort:
nm_channels = nm_define_nmchannels.get_default_channels_from_data(
data, car_rereferencing=True
)
nm_channels
Using this function default channel names and a common average re-referencing scheme is specified. Alternatively the nm_define_nmchannels.set_channels function can be used to pass each column values.
nm_settings#
Next, we will initialize the nm_settings dictionary and use the default settings, reset them, and enable a subset of features:
The setting itself is a .json file which contains the parametrization for preprocessing, feature estimation, postprocessing and definition with which sampling rate features are being calculated. In this example sampling_rate_features_hz is specified to be 10 Hz, so every 100ms a new set of features is calculated.
For many features the segment_length_features_ms specifies the time dimension of the raw signal being used for feature calculation. Here it is specified to be 1000 ms.
We will now enable the features:
fft
bursts
sharpwave
and stay with the default preprcessing methods:
notch_filter
re_referencing
and use z-score postprocessing normalization.
We are now ready to go to instantiate the Stream and call the run method for feature estimation:
stream = nm.Stream(
settings=settings,
nm_channels=nm_channels,
verbose=True,
sfreq=sfreq,
line_noise=50,
)
features = stream.run(data)
Last batch took: 0.04 seconds
1.0 seconds of data processed
Last batch took: 0.04 seconds
1.1 seconds of data processed
Last batch took: 0.04 seconds
1.2 seconds of data processed
Last batch took: 0.03 seconds
1.3 seconds of data processed
Last batch took: 0.04 seconds
1.4 seconds of data processed
Last batch took: 0.04 seconds
1.5 seconds of data processed
Last batch took: 0.04 seconds
1.6 seconds of data processed
Last batch took: 0.04 seconds
1.7 seconds of data processed
Last batch took: 0.04 seconds
1.8 seconds of data processed
Last batch took: 0.04 seconds
1.9 seconds of data processed
Last batch took: 0.04 seconds
2.0 seconds of data processed
Last batch took: 0.04 seconds
2.1 seconds of data processed
Last batch took: 0.04 seconds
2.2 seconds of data processed
Last batch took: 0.04 seconds
2.3 seconds of data processed
Last batch took: 0.04 seconds
2.4 seconds of data processed
Last batch took: 0.04 seconds
2.5 seconds of data processed
Last batch took: 0.04 seconds
2.6 seconds of data processed
Last batch took: 0.04 seconds
2.7 seconds of data processed
Last batch took: 0.04 seconds
2.8 seconds of data processed
Last batch took: 0.04 seconds
2.9 seconds of data processed
Last batch took: 0.04 seconds
3.0 seconds of data processed
Last batch took: 0.04 seconds
3.1 seconds of data processed
Last batch took: 0.04 seconds
3.2 seconds of data processed
Last batch took: 0.04 seconds
3.3 seconds of data processed
Last batch took: 0.04 seconds
3.4 seconds of data processed
Last batch took: 0.04 seconds
3.5 seconds of data processed
Last batch took: 0.04 seconds
3.6 seconds of data processed
Last batch took: 0.04 seconds
3.7 seconds of data processed
Last batch took: 0.04 seconds
3.8 seconds of data processed
Last batch took: 0.04 seconds
3.9 seconds of data processed
Last batch took: 0.04 seconds
4.0 seconds of data processed
Last batch took: 0.04 seconds
4.1 seconds of data processed
Last batch took: 0.04 seconds
4.2 seconds of data processed
Last batch took: 0.04 seconds
4.3 seconds of data processed
Last batch took: 0.04 seconds
4.4 seconds of data processed
Last batch took: 0.04 seconds
4.5 seconds of data processed
Last batch took: 0.04 seconds
4.6 seconds of data processed
Last batch took: 0.04 seconds
4.7 seconds of data processed
Last batch took: 0.04 seconds
4.8 seconds of data processed
Last batch took: 0.04 seconds
4.9 seconds of data processed
Last batch took: 0.04 seconds
5.0 seconds of data processed
Last batch took: 0.04 seconds
5.1 seconds of data processed
Last batch took: 0.04 seconds
5.2 seconds of data processed
Last batch took: 0.04 seconds
5.3 seconds of data processed
Last batch took: 0.04 seconds
5.4 seconds of data processed
Last batch took: 0.04 seconds
5.5 seconds of data processed
Last batch took: 0.04 seconds
5.6 seconds of data processed
Last batch took: 0.04 seconds
5.7 seconds of data processed
Last batch took: 0.04 seconds
5.8 seconds of data processed
Last batch took: 0.04 seconds
5.9 seconds of data processed
Last batch took: 0.04 seconds
6.0 seconds of data processed
Last batch took: 0.04 seconds
6.1 seconds of data processed
Last batch took: 0.04 seconds
6.2 seconds of data processed
Last batch took: 0.04 seconds
6.3 seconds of data processed
Last batch took: 0.04 seconds
6.4 seconds of data processed
Last batch took: 0.04 seconds
6.5 seconds of data processed
Last batch took: 0.04 seconds
6.6 seconds of data processed
Last batch took: 0.04 seconds
6.7 seconds of data processed
Last batch took: 0.04 seconds
6.8 seconds of data processed
Last batch took: 0.04 seconds
6.9 seconds of data processed
Last batch took: 0.04 seconds
7.0 seconds of data processed
Last batch took: 0.04 seconds
7.1 seconds of data processed
Last batch took: 0.04 seconds
7.2 seconds of data processed
Last batch took: 0.04 seconds
7.3 seconds of data processed
Last batch took: 0.05 seconds
7.4 seconds of data processed
Last batch took: 0.05 seconds
7.5 seconds of data processed
Last batch took: 0.05 seconds
7.6 seconds of data processed
Last batch took: 0.05 seconds
7.7 seconds of data processed
Last batch took: 0.04 seconds
7.8 seconds of data processed
Last batch took: 0.04 seconds
7.9 seconds of data processed
Last batch took: 0.04 seconds
8.0 seconds of data processed
Last batch took: 0.04 seconds
8.1 seconds of data processed
Last batch took: 0.04 seconds
8.2 seconds of data processed
Last batch took: 0.04 seconds
8.3 seconds of data processed
Last batch took: 0.04 seconds
8.4 seconds of data processed
Last batch took: 0.04 seconds
8.5 seconds of data processed
Last batch took: 0.04 seconds
8.6 seconds of data processed
Last batch took: 0.04 seconds
8.7 seconds of data processed
Last batch took: 0.04 seconds
8.8 seconds of data processed
Last batch took: 0.04 seconds
8.9 seconds of data processed
Last batch took: 0.04 seconds
9.0 seconds of data processed
Last batch took: 0.04 seconds
9.1 seconds of data processed
Last batch took: 0.04 seconds
9.2 seconds of data processed
Last batch took: 0.04 seconds
9.3 seconds of data processed
Last batch took: 0.04 seconds
9.4 seconds of data processed
Last batch took: 0.04 seconds
9.5 seconds of data processed
Last batch took: 0.04 seconds
9.6 seconds of data processed
Last batch took: 0.04 seconds
9.7 seconds of data processed
Last batch took: 0.04 seconds
9.8 seconds of data processed
Last batch took: 0.04 seconds
9.9 seconds of data processed
Last batch took: 0.04 seconds
10.0 seconds of data processed
_SIDECAR.json saved to /home/docs/checkouts/readthedocs.org/user_builds/py-neuromodulation/checkouts/latest/examples/sub/sub_SIDECAR.json
FEATURES.csv saved to /home/docs/checkouts/readthedocs.org/user_builds/py-neuromodulation/checkouts/latest/examples/sub/sub_FEATURES.csv
settings.json saved to /home/docs/checkouts/readthedocs.org/user_builds/py-neuromodulation/checkouts/latest/examples/sub/sub_SETTINGS.json
nm_channels.csv saved to /home/docs/checkouts/readthedocs.org/user_builds/py-neuromodulation/checkouts/latest/examples/sub/sub_nm_channels.csv
Feature Analysis#
There is a lot of output, which we could omit by verbose being False, but let’s have a look what was being computed.
We will therefore use the nm_analysis class to showcase some functions. For multi-run -or subject analysis we will pass here the feature_file “sub” as default directory:
analyzer = nm_analysis.Feature_Reader(
feature_dir=stream.PATH_OUT, feature_file=stream.PATH_OUT_folder_name
)
Let’s have a look at the resulting “feature_arr” DataFrame:
analyzer.feature_arr.iloc[:10, :7]
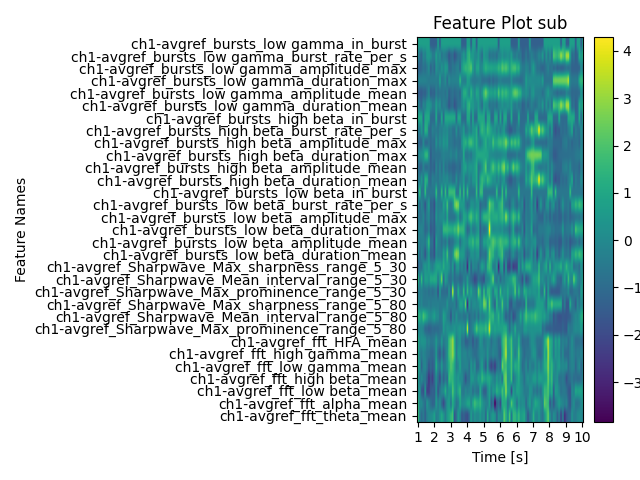
Seems like a lot of features were calculated. The time column tells us about each row time index. For the 6 specified channels, it is each 31 features. We can now use some in-built plotting functions for visualization.
Note
Due to the nature of simulated data, some of the features have constant values, which are not displayed through the image normalization.
analyzer.plot_all_features(ch_used="ch1")
nm_plots.plot_corr_matrix(
figsize=(25, 25),
show_plot=True,
feature=analyzer.feature_arr,
)
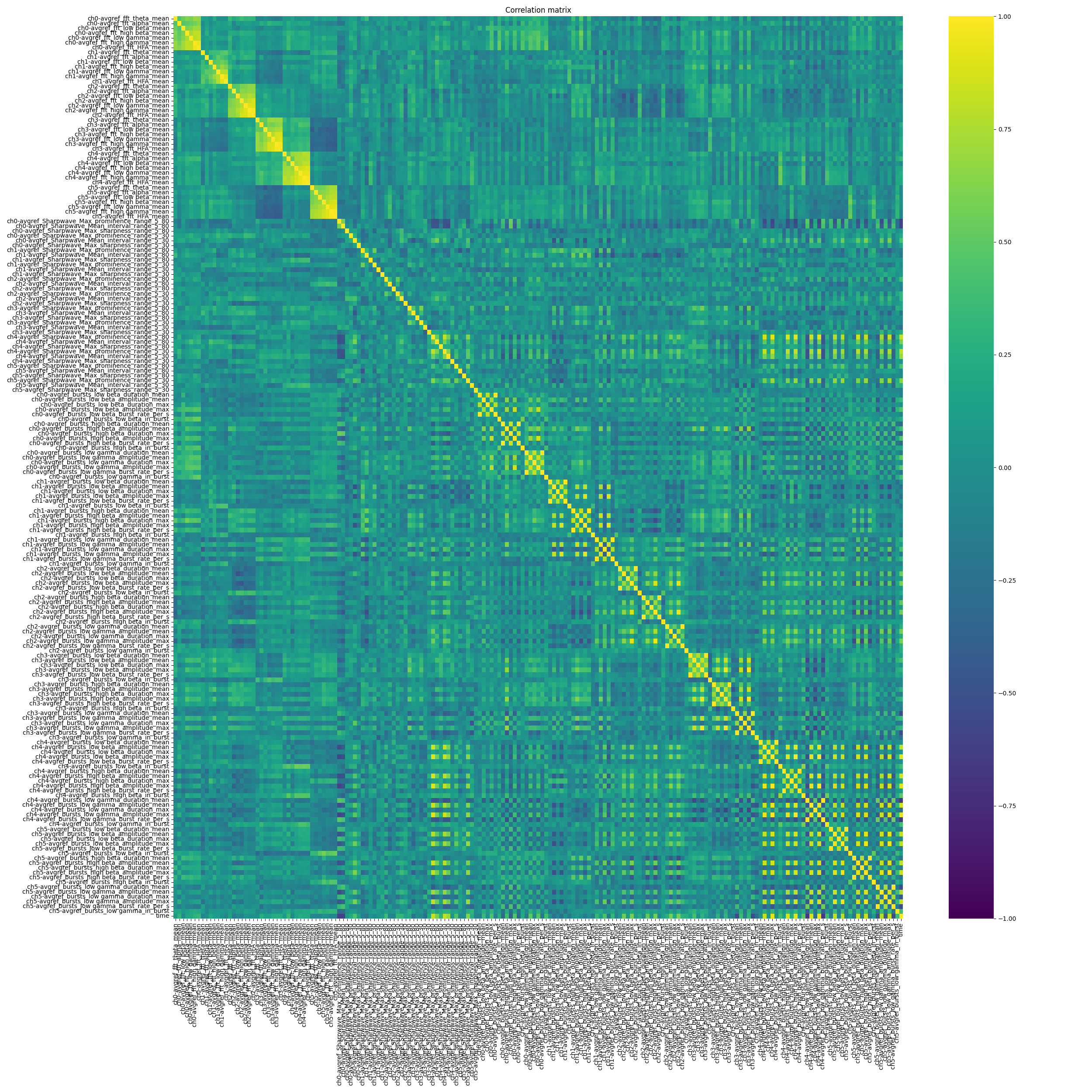
<Axes: title={'center': 'Correlation matrix'}>
The upper correlation matrix shows the correlation of every feature of every channel to every other. This notebook demonstrated a first demo how features can quickly be generated. For further feature modalities and decoding applications check out the next notebooks.
Total running time of the script: (0 minutes 8.199 seconds)